
Home / Blog / Design / 11 Dicembre 2020Data Visualization: visualizzare i Big Data
Big data è una locuzione che indica una raccolta di dati molto estesa in termini di volume ed eterogenea, tanto da necessitare di tecnologie e metodi analitici specifici per il loro studio e la loro interpretazione. Riconosciamo due principali tipologie di big data, ovvero i dati strutturati (ad esempio le informazioni scritte in codici HTML) e dati destrutturati (testo, audio, video, foto, etc.). Il loro accesso e la loro memorizzazione sono già possibili dalla fine del secolo scorso, anche se il vero e proprio concetto di big data sale alla ribalta nei primi anni 2000. Il primo a farne una definizione ben precisa fu l’analista di mercato Doug Laney nel 2001, che li identificò con tre principali attributi:
- Volume: le organizzazioni raccolgono dati da diverse fonti, a partire dalle transazioni commerciali, dispositivi intelligenti, finire per video, foto e materiale proveniente da tutti i social media e tanto altro ancora. Oggi è decisamente più semplice poter memorizzare e archiviare i big data, grazie a piattaforme come i data lakes e Hadoop;
- Velocità: con un Internet of Things sempre più presente, è fondamentale organizzare i flussi di dati in modo tempestivo e a una velocità senza precedenti;
- Varietà: i big data sono, chiaramente, estremamente vari ed eterogenei, presenti in tantissimi tipi di formati, dai dati strutturati e numerici nei database tradizionali, ai documenti di testo non strutturati, e-mail, video, audio, dati di stock e transazioni finanziarie.
Questa definizione di Laney fu arricchita con altre due “V”:
- Valore: i big data possiedono un valore inestimabile, ma per essere utili devono essere elaborati. Quindi è fondamentale che le persone sappiano quali utilizzare, e con quali strumenti, per raggiungere i loro obiettivi. Per esempio, si possono utilizzare le metodologie dei big data per verificare il ritorno d’investimento (ROI) di campagne multi canale di Marketing.
- Viralità: i dati digitali, sono destrutturati e, vista l’elevata probabilità di essere sporchi, necessitano di essere puliti. Questo significa migliorare ulteriormente gli strumenti per rendere i dati più affidabili. Per esempio, posso sapere quali sono i commenti che vengono fatti nei social media e nei social network, nei siti di settore su un nuovo prodotto, come i consumatori percepiscono i punti di forza e di debolezza e altro ancora.
Tipi di analisi dei Big Data
Le cinque “V” sono utili per capire le caratteristiche dei big data, quanto sono importanti e, soprattutto, la loro funzione, che è quella di spiegare nel modo migliore possibile la realtà, attraverso la loro interpretazione. Vista la loro mole, le metodologie tradizionali di analisi dei dati non sono sempre sufficienti, ed è necessario sviluppare processi ben precisi con fasi di verifica e controllo. Appare utile, in questo caso, applicare una metodologia di tipo Data Driven con quattro tipi di Data Analysis:
- Analisi descrittiva: è costituita dai tool che permettono di rappresentare e descrivere la realtà spiegata dai dati. Nel caso delle imprese si può trattare, ad esempio, di rappresentare i processi interni;
- Analisi predittiva: è basata su soluzioni che permettono di effettuare l’analisi dei dati al fine di disegnare scenari di sviluppo nel futuro. Le tecniche più usate sono i modelli predittivi e i forecasting;
- Analisi prescrittiva: in questa circostanza, si parla di strumenti che associano l’analisi dei dati alla capacità di assumere e gestire processi decisionali. Le analisi prescrittive sono tool che indicano strategie o soluzioni operative basate sia sull’analisi descrittiva sia sulle analisi predittive;
- Analisi automatizzate: permettono di entrare nell’ambito dell’automazione con soluzioni di Analytics. A fronte dei risultati delle analisi descrittive e predittive, le analisi automatizzate sono in condizione di attivare delle azioni definite sulla base di regole, che possono essere a loro volta il frutto di un processo di analisi.
Data Visualization vs Infografica
Per estrapolare informazioni dai Big Data è necessario avvalersi di una serie di metodologie di analisi, ma anche di sistemi adatti per la loro rappresentazione. Rispetto alle classiche tabelle che raccolgono i dati in lunghi elenchi di righe e colonne, la visualizzazione dei dati mostra nuove pratiche visive per guidare l’utente nell’esplorazione semantica dei grandi set di dati. L’obiettivo principale di queste rappresentazioni è quello di creare un nuovo linguaggio che sia facilmente comprensibile e che riproduca al meglio il complesso fenomeno dei Big Data. Due sono le modalità principali per la rappresentazione di un insieme di dati: le infografiche e le data visualization. Entrambe riproducono graficamente un data set ma con alcune differenze nella struttura e negli intenti.
- Infografica. Il neologismo nasce dall’unione di information e graphic. Si tratta di un prodotto digitale o analogico che permette attraverso l’elaborazione grafica di un set di dati permette di raccontare una storia specifica o presentare un singolo aspetto di interesse dell’insieme di dati. L’infografica spesso è accompagnata da altri tipi di linguaggio come mappe, illustrazioni, video o porzioni di testo.
- Data visualization. Si tratta di uno strumento di codifica visiva dei dati, elaborato principalmente in digitale. Permette all’utente di esplorare in maniera più libera i dati creando diversi tipi di associazioni. Al contrario dell’infografica, la data visualization non mostra una sola prospettiva, ma presenta il set di dati in maniera più organica e completa. Anche all’interno di aziende dei settori più diversi, gli strumenti e le tecnologie della visualizzazione dati sono fondamentali per analizzare grandi quantità di informazioni e compiere decisioni data-driven.
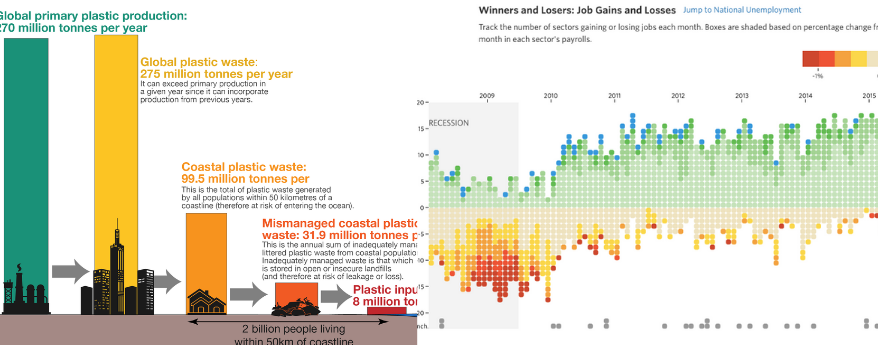
A sinistra esempio di infografica; a destra esempio di data visualization
Oggettività e costruzione di significato
Alberto Cairo, uno dei massimi esperti della visualizzazione dati, inserisce le teorie e le tecnologie necessarie per la gestione e l’organizzazione dei dati all’interno dell’Architettura dell’informazione. L’Architettura dell’informazione si occupa più in generale della sistemazione di contenuti e informazioni per un qualsiasi prodotto (digitale e non). Secondo Cairo, infatti, le visualizzazioni dei dati sono principalmente uno strumento che permette di ordinare complessi fenomeni del reale. Nel suo libro The Functional Art (2012, p.18), in maniera significativa, cita un passo di Joan Costa, professore di Design sul concetto di visualizzazione. “To visualize is to make certain phenomena and portions of reality visible and understandable: many of these phenomena are not naturally accessible to the bare eye, and many of them are not even of visual nature”.
Seguendo la posizione di Cairo, si comprende come la progettazione (design), che permette alla visualizzazione di dare ordine al reale, sia l’aspetto più rilevante e caratterizzante della data visualization, ancor prima dei suoi contenuti. La data visualization è “the art and science of preparing information so that it can be used by human beings with efficiency and effectiveness”. (Horn)
In questo senso, allora, i raw data devono essere considerati come una “materia amorfa”, che ha bisogno di un progetto preciso o di un punto di vista per potersi strutturare in informazione. I dati, di per sé, non sono né informazione, né uno strumento oggettivo di conoscenza. In questo senso, Ciuccarelli parla di significato “costruito”, non estratto. Più che Data Mining (estrazione di informazioni dai dati) la visualizzazione dati è un processo di “sense-making”: analisi, elaborazione e interpretazione (del designer) di un insieme di dati. “ We have to make it [meaning], and –before that – design it”. (Ciuccarelli)
Dinamicità dei dati
Negli ultimi anni, i designer dell’informazione si sono impegnati ad elaborare strategie visive che mostrano la dinamicità e la mutevolezza dei dati. L’obiettivo è anche quello di sfatare il mito dei dati come strumenti assolutamente oggettivi.
Si è passati da una prima fase, in cui si rappresentavano semplicemente i flussi di dati, ad una seconda, in cui si rappresenta il sistema di dati soggetto al cambiamento dei parametri e delle relazioni con altri data set che ne influenzano la struttura (e il significato). Questo tipo di visualizzazione trova la massima realizzazione nelle data visualization interattive online.
WORLD POTUS è un esempio molto interessante. Si tratta di una web application sviluppata dallo studio milanese Accurat in collaborazione con Google News Lab, e mostra quale tra i due candidati, Clinton e Trump, delle precedenti elezioni statunitensi avrebbero votato le persone residenti al di fuori degli USA. Tuttavia proprio il tipo di dati utilizzati, quelli raccolti da Google Trends, e la forma di rappresentazione sviluppata da Accurat cercano di andare oltre la tradizionale concezione dei dati come strumento di verità. L’esperimento dimostra come le opinioni su tematiche così delicate sono spesso fluide e mutevoli, così come i dati che le rappresentano. “The Google Trends Index is a valuable and insghitful way to gauge the general sense of a country’s interest topic over time, but it shouldn’t be considered a perfect and ultimate measure of it” (Accurat). Più avanti lo studio parla proprio di “fuzziness” legata alle conversazioni online.
Un giornalismo di soli dati
Con l’avvento di Internet il paradigma delle pratiche e degli strumenti giornalistici è profondamente cambiato. Non si fa riferimento solo all’avvento delle testate online, ma al più generale ripensamento dei linguaggi disponibili per il giornalismo. Una tendenza ormai ben riconoscibile dagli inizi degli anni 10 del 2000 è il “data driven Journalism” ovvero quel tipo di giornalismo basato interamente sull’analisi e l’interpretazione dei dati. Il New York Times, Bloomberg e The Guardian sono state le prime redazioni al mondo ad aver esplorato le possibilità offerte dalla visualizzazione dei dati. Al punto che Matt Daniels ha affermato: “Lately, some of the best articles in the NY Times and Bloomberg are 99% code. The end-product is predominantly software, not prose.”
In Italia è opportuno ricordare almeno l’esperimento di Dataroom del Corriere della Sera condotto da Milena Gabanelli. Con cadenza settimanale, la “regina delle inchieste” in Italia analizza alcuni temi di interesse politico e culturale a partire da set di dati. L’operazione, oltre che essere estremamente interessante per il tipo di format sviluppato (inchieste multimediali con testi scritti, video, immagini, grafici etc.), introduce anche in Italia la pratica del “data driven journalism” di alto livello.
Per approfondire:
- Agcom > Report sui Big Data
- Digicult > Intervista a Giorgia Lupi. Dati non solo numeri
- The Upshot > The best and worst place to grow up
cover image credit: The Met (Object: 471743/ Accession: 56.171.74a, b)